
Aplicações mais performáticas com DBLess Architecture
Como otimizar a performance das suas aplicações removendo o Banco de Dados

Recentemente vi essa discussão em um post da RedisLabs e achei a provocação interessante. Caso queira conferir o post é esse aqui: Post sobre DBLess Architecture
O que existe de mais comum em Desenvolvimento Web é o gargalo da aplicação estar no Banco de Dados. Dito isto, como podemos melhorar a performance das nossas aplicações? Removendo o Banco de Dados!

Como assim? E meus dados, vão para onde?
Muita calma que tudo vai ficar claro. A ideia não é criar aplicações sem banco de dados, e sim, fazer um pequeno ajuste na Arquitetura Tradicional. Mas, para entendermos o que muda com essa arquitetura, é necessário entendermos como grande parte das aplicações web são desenhadas atualmente.
Arquitetura Tradicional
Em linhas gerais, pode-se dizer que a maior parte das aplicações web são divididas basicamente em 3 componentes:
- A sua aplicação, rodando em um App/Web Server
- Um banco de dados primário, responsável pelo armazenamento e operações de CRUD nos seus dados
- E um banco de dados secundário que pode ser utilizado para diversas finalidades, por exemplo, cache, sistema de filas, rate limit, etc. Sendo, o sistema de cache, o caso mais comum.
Isso geralmente acontece pois respostas vindas de bancos de dados "tradicionais" são lentas, por conta disso, é interessante colocar na frente do seu banco de dados um sistema de cache que possar servir os dados requisitados de forma mais rápida.
Uma solução bastante utilizado para sistemas de cache é o Redis. Bancos de dados como o Redis são chamados de in memory databases, ou seja, os dados são armazenados em memória e isso permite que sejam ordens de grandeza mais rápidos que Bancos que armazenam seus dados em disco.
Abaixo podemos ver um design muito comum de uma aplicação Web:
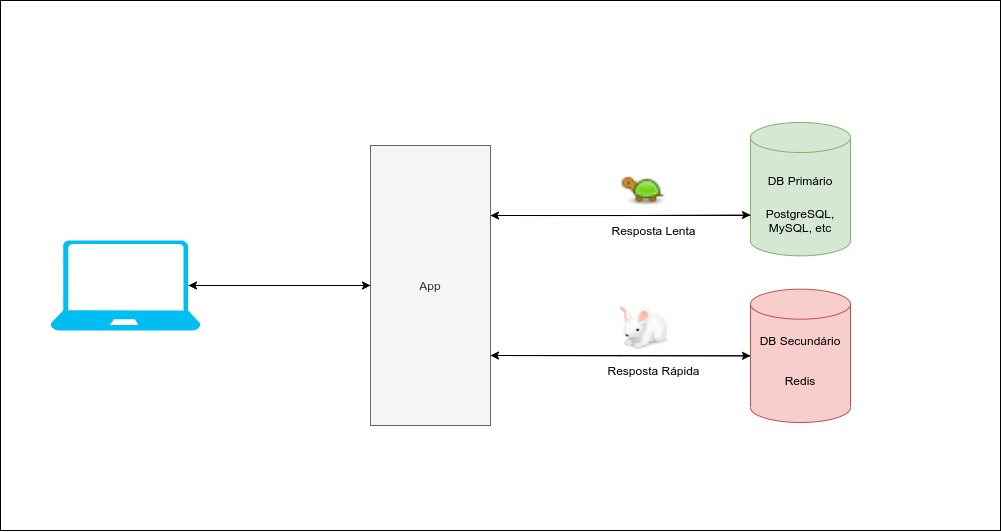
O usuário faz uma requisição para o seu App, primeiramente, ele consulta a disponibilidade dos dados no sistema de cache. Caso os dados estejam disponíveis no cache, temos um cache hit, caso contrário um cache miss.
Em casos de cache miss, seu app vai precisar buscar essas informações no seu Banco de Dados Primário, que como dito anteriormente, tem uma resposta relativamente lenta. Agora, quando temos um cache hit, o sistema de cache já retorna os dados requisitados, fazendo com que o usuário receba a resposta de forma muito mais rápida.
Note que, sempre que ocorrer um hit no cache, o seu Banco de Dados Secundário estará assumindo uma responsabilidade que seria do seu Banco Primário, servir os dados para o usuário.
Já que o Banco de Dados Secundário é muito mais rápido, seria possível utilizá-lo como Banco Primário? Ou seja, transferir não só a responsabilidade de leitura mas sim todas as outras (create, update, delete)? Sim! É essa a proposta da DBLess Architecture!
DBLess Architecture
A ideia da DBLess Architecture é substituir seu Banco de Dados Primário (MySQL, PostgreSQL, SQLServer, etc) por um banco de dados como o Redis, geralmente utilizado como um Banco de Dados Secundário, mas muito mais rápido.
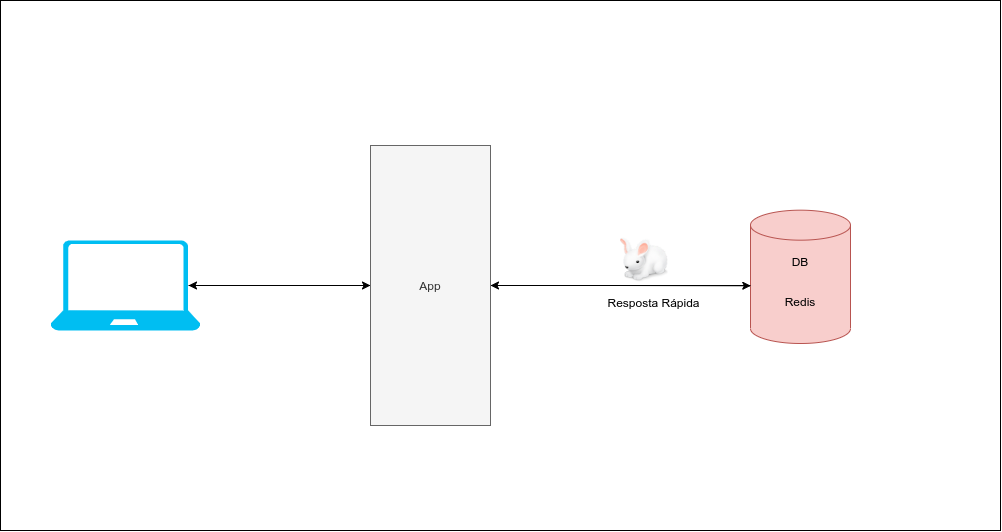
Lembrando que qualquer outro banco com características semelhantes as do Redis poderia ser utilizado.
Claro que, antes de sair aplicando essa solução em seus projetos é importante avaliar os casos de uso onde uma mudança como essa realmente faz sentido. O mais interessante da discussão é pensar, será que no futuro esse tipo de abordagem será comum?
Ok, mas até agora foi só blablabla teoria. Caso essa abordagem se encaixe em alguma necessidade nossa, seria possível implementar uma solução assim? Claro!
Vamos criar um projeto onde possamos ver na prática esse tipo de arquitetura.
O Projeto
Vamos criar um encurtador de URLs. Criaremos uma API simples, onde será possível realizarmos as seguintes operações:
- Cadastrar um usuário
- Criar um link encurtado associado a um usuário
- Consultar a url original dado um slug
- E quantificar quantas visitas um link encurtado recebeu
Nosso principal objetivo é entendermos como aplicar a DBLess Architecture que vimos anteriormente. Para isso vamos precisar de:
- Um framework web para a criação da nossa API
- Um banco de dados in memory, no nosso caso, o Redis
- E, para facilitar nosso trabalho, utilizaremos a biblioteca Ohm. Ela será nosso "ORM" para o Redis.
Framework Web
Utilizaremos o micro framework Sinatra para construir nossa API, mas você poderá utilizar o framework de sua preferência. Optei pelo Sinatra para mantermos nosso projeto simples e porque Ruby é uma das minhas linguagens preferidas (❤️). Mas praticamente qualquer linguagem tem algo parecido, por exemplo, o Express no Node ou o Flask no Python.
De qualquer forma, vou deixar um docker-compose prontinho com a stack para você rodar se quiser 🙂
Redis
Outro ponto, extremamente necessário, para que tudo funcione é realizar as configurações de persistência do nosso Redis. As opções de persistência fornecidas pelo Redis são RDB (Redis Database), AOF (Append Only File) ou sem persistência.
Como queremos manter nossos dados armazenados no Redis, mesmo após uma reinicialização ou qualquer outra coisa que venha a derrubar o servidor, nossas opções de persistência são utilizarmos RDB, AOF ou uma combinação de ambos. Para o nosso caso apenas o AOF será suficiente!
❓ Caso queria entender melhor as opções de Persistência do Redis e quando utilizar cada uma, deixe um comentário aqui embaixo, assim eu posso fazer um post explicando tudo 🙂
Ohm
Como dito anteriormente, essa biblioteca vai facilitar bastante o nosso trabalho, com ela conseguimos definir atributos dos nossos modelos, índices, ordenação, unicidade, etc. Tudo de forma bem simples. No nosso caso, utilizaremos a versão em Ruby, mas existem implementações em várias linguagens, como pode ser visto no link do Github deles que vou deixar aqui: Ohm Github.

Ok, então vamos lá! 🧑💻
Se quiser acompanhar comigo, já faz o clone do projeto que está no GitHub
Primeiramente vamos adicionar nossos modelos, vamos precisar de um modelo para nossos usuários, no caso, User e outro para os links encurtados que chamaremos de Link.
# user.rb
...
class User < Ohm::Model
attribute :name
index :name
unique :name
collection :links, :Link
end
Caso você não seja do mundo Ruby pode estranhar a sintaxe, mas basicamente estamos fazendo o seguinte:
- Definindo um atributo
namepara nosso modeloUser - Adicionando um índice ao
name(É necessário para utilizarmosModel#find) - Definindo que o atributo
nameserá único - E associando uma coleção de links ao nosso usuário
E agora vamos definir nosso modelo de Links.
# link.rb
...
class Link < Ohm::Model
attribute :slug
index :slug
unique :slug
attribute :url
reference :user, :User
counter :views
...
end
A configuração do nosso modelo de Link é similar a de User, mas, com algumas adições interessantes:
- Estamos definindo 2 atributos
slugeurl, no entanto, adicionamos aoslugum índice assim como o critério de unicidade - Adicionamos a referência para os usuários, no caso, os donos dos links
- Por fim, adicionamos um contador para quantificarmos as visitas em um determinado link
Com nosso modelos definidos vamos partir para as rotas da nossa API.
Rotas API
| METHOD | PATH | OBS |
| GET | / | Lista todos os links cadastrados |
| POST | /links | Cadastra um novo Link body: { slug: string, url: string, user_id: integer } |
| GET | /links/search/:slug | Busca um link correspondente ao slug informado |
| POST | /users | Cadastra um novo usuário body: { name: string } |
| POST | /seed | Rota de teste, adiciona 1 mil links para cada usuário cadastrado |
❗ Caso tenha optado por utilizar o docker-compose essa é a hora de rodar um
docker-compose up🐳
Para começar vamos criar alguns usuários, para isso vou utilizar o curl mas fique à vontade para utilizar o client de sua preferência 🙂
curl -X POST -H 'Content-Type: application/json' -d '{"name": "user1"}' http://localhost:4567/users
# => {"name":"user1"}
Com o nosso usuário criado vou utilizar a nossa rota de testes /seed para criar 1 mil links associados a esse usuário
curl -X POST -H 'Content-Type: application/json' http://localhost:4567/seed
Feito isso, podemos consultar todos os links criados dessa forma:
curl http://localhost:4567/
# =>
# [
# {
# "slug": "3ify",
# "url": "http://kuhic.io/antonina",
# "views": 0
# },
# ...
# ]
Vou utilizar a primeira ocorrência retornada pela requisição anterior para testar a busca de um link por slug, mas antes, vamos testar nossa persistência?
Para isso vamos simular um reboot do sistema, derrubando nossos contêineres e subindo tudo novamente. Vamos utilizar o comando docker-compose rm -f para removermos os contêineres, a flag -f faz a execução ser forçada, ou seja, não receberemos nenhum pedido de confirmação.
E agora, vamos subir tudo novamente com docker-compose up e refazer a nossa requisição de listagem de links:
curl http://localhost:4567/
# =>
# [
# {
# "slug": "3ify",
# "url": "http://kuhic.io/antonina",
# "views": 0
# },
# ...
# ]

Aí sim, tudo funcionando! 👏
E agora, vamos realizar nossa busca por slug. Para isso vamos fazer a seguinte requisição:
curl http://localhost:4567/links/search/3ify
# => {"slug":"3ify","url":"http://kuhic.io/antonina","views":1}
Pronto! Conseguimos implementar todas as funcionalidades necessárias e nossos dados estão persistidos como se estivéssemos utilizando um Banco de Dados tradicional.
Conclusão
Vimos que é possível implementar essa tal "DBLess Architecture" e utilizar apenas o Redis para realizar todas as operações com nossos dados. Não chegamos a implementar rotas para update e delete, mas utilizando um "ORM", como no nosso caso, isso tudo se torna bem fácil.
Deixo esse desafio para você! 👊
Existe todo um ferramental pronto para lidarmos com dados no Redis, e caso necessário, ainda temos diversas opções de garantias que podemos utilizar, já que quando implementamos uma Arquitetura assim deixamos de ter os benefícios de Bancos de dados tradicionais, em troca de uma performance bem melhor.
Mas, é sempre uma troca! Caso sua aplicação realmente necessite de operações ACID essa provavelmente não será a melhor estratégia. Mas existem casos onde ela se aplica muito bem, inclusive, existe o case da Request Metrics onde eles construíram um produto inteiro utilizando essa Arquitetura.
Vou me despedindo por aqui 🙂. Mas você pode consultar todos os detalhes do projeto que fizemos nesse link do GitHub.
E você, gostou desse post? Você também é um fã do Redis? Gostaria de ver um comparativo entre as abordagens citadas?
Ficou com alguma dúvida? Comenta aqui embaixo e a gente conversa.
Forte abraço, até a próxima!
